
Tl;dr: What would happen to your funds in Zengo if we (or your favorite wallet) stopped operating? Zengo guaranteed access (aka Chill Storage) is our answer to providing full peace of mind and we are bringing today an innovative approach to building an even more robust and trusted solution.
Introduction
Zengo’s Keyless Wallet technology, which replaces the traditional private key with two independently created “mathematical secret shares”, is designed to ensure that our customer’s asset security will never be impacted by a “single point of failure”. Since one share is stored on the customer’s mobile device (“Client”), and the other on the Zengo server (“Server”), assets will be kept safe and sound even if one of the shares gets compromised.
This keyless approach utilizes Distributed Key Generation (DKG), in which secret shares are generated in distributed fashion and are never reconstructed, and threshold signatures in place of regular digital signatures, which are computed while keeping the secret key`s secret shares private.
One unique aspect of this design is that our servers manage a unique secret share for every user – without this the client cannot produce a signature. This however introduced a crucial tradeoff to our “no-single-point-of-failure” design: recovery became complex!
At launch we deployed our existing solution – named Guaranteed Access, This solution is by now battle tested and has received great market validation. However, we never stopped working on the recovery problem, which we believe is one of the most important to tackle in any key management system. We are always pushing for new innovations that will meet our standard of elegance, security and efficiency.
In this blog, we will focus on server-side secret share recovery (as opposed to client share recovery, in which a backup system is used to recover stolen or lost user`s mobile device). More specifically, we will answer the question, “How do we protect the server secret share in the event of a Zengo server failure?”
Zengo Chill Storage
Although a server failure can mean many things, for the purpose of this blog server failures refer to any scenario in which the server becomes unavailable for a prolonged period of time. It can occur as a result of an attack, inside job, force majeure, or even cessation of Zengo company operations. Despite the fact that these events are highly unlikely to occur, we took all possible measures to guarantee our users the continuous accessibility to their funds ,and deployed our first solution to proactively address these issues – We call it guaranteed access (aka Chill Storage)
Before introducing our latest approach, let’s briefly cover this existing, already deployed solution. For more detailed information you can read this, followed by this.
Our approach required us to introduce two new physical entities.
- The Trustee – a legal entity operating under the laws of the state of Israel. The Trustee is in charge of sampling the status and “health” of Zengo from a business perspective (i.e. Zengo the “company”). In the event that the Trustee identifies an issue with the above (i.e. determines that no “proof of life” exists), it triggers a second entity, the “Escrow”.
- The Escrow – This entity holds a global decryption key inside a vault. Once triggered, the Escrow will release the decryption key on a dedicated GitHub repo. In turn, the app will download the global decryption key and use it locally to decrypt the server secret share, which was originally encrypted and sent to each client as part of the key generation process.
There is some new cryptography involved in this approach as well. Since the server sends the client a “sealed box” which the client cannot open until the Trustee triggers the Escrow, we require the server to provide zero knowledge proof to the client that the sealed box (1) contains the server secret share that matches the client, and (2) that it can be decrypted using a key held by the Escrow. To make sure the Escrow holds the global decryption key at all times, the Escrow periodically publishes a signature on a fresh public challenge (e.g. a daily newspaper) for all to verify. Finally, we note that our solution respects our design rule of no single point of failure.
Can we do better?
While the Guaranteed access was never triggered, except for simulations and dry runs, the CS1.0 approach worked well and was received positively by our customers. However, some critique and valid concerns do exist. We thank our dedicated users who provided us with insightful feedback through interviews and while engaging with customer support.
First, we noted that our solution is dependent on two third-parties, and is not “jurisdiction agnostic”. Ideally, we want to eliminate third party dependencies whenever possible. We have legal agreements in place with both, and if an issue arises with either party, we assume that Zengo is operational and able to resolve it. However, this in a sense forces our users to be dependent on Israeli legal procedures to resolve any issues. While our legal agreements are public, they require a thorough review and some level of familiarity with legal jargon to understand them.
Our new solution eliminates this unnecessary friction by replacing the Trustee and Escrow functions with a digital native equivalent, as we will explain below.
Second, our existing solution has room to improve on the cryptography end. In particular, the zero knowledge proof is secure, but it involves non-trivial cryptography implemented in-house. It is always better to rely on more established cryptography and battle-tested libraries.
This brings us to our newest approach! Chill Storage version 2.0 marries “time-based cryptography” and a trusted execution environment to address the issues mentioned above. Let’s begin!
The Foundations of Chill Storage 2.0
We now sketch the components of our new approach and the recent breakthroughs that made it possible.
- Trusted execution environment (TEE): a TEE is a computing platform that supports confidential computing. TEE guarantees the integrity and confidentiality of the computation. In theory, an outsider cannot learn anything about computation that happens inside the secure enclave. Nowadays, a TEE is an integral part of most modern CPUs. In recent years, TEE became available as a service in various cloud computing platforms such as AWS and Azure.
As they have grown in popularity, TEEs have also received a significant amount of spotlight from the cybersecurity community. Demonstrations of acute attacks were shown. Instead of being naive to such attacks, we will later demonstrate how our code can be optimized to put less trust on the TEE confidentiality property.
- Time Based Cryptography: This is a type of cryptography that relies on moderately hard functions (instead of hard to solve functions), which means that given a reasonable amount of time it is possible to break the time based cryptographic primitive. We in particular are interested in one type of time based cryptography – a Verifiable Delay Function (VDF). A VDF is parameterized with a time parameter ‘T’ that determines the time it takes to solve the VDF (e.g 1 week / 1 month / 1 year etc..).
VDF is composed of the following set of algorithms:
a) Challenge: generates a challenge ‘C’
b) Solve: computes VDF(C), get a solution ‘S’
c) Verify: checks that ‘S’ is a VDF solution to ‘C’
We note and use the fact that Verify is much ( much much!) faster than Solve.
- CryptoWill: This is the glue that connects the TEE and the VDF. CryptoWill : How to Bequeath Cryptoassets is the title of a recent paper we published in which we define an interface for crypto asset inheritance and provide a TEE-based construction. The main challenge we covered was how a TEE can obtain “proof of life” from a testator so that it will release the bequeath to the beneficiary at the right time (which is likely when the testator is not able to provide “proof of life” anymore). The trick we introduce in the paper is to have the TEE generate a fresh VDF challenge for a beneficiary requesting the bequeath. The beneficiary will run the Solve algorithm locally to compute the VDF. Once solved, the beneficiary will submit the solution to the TEE for verification. If the VDF was verified correctly for the original challenge the TEE program can know for sure that at least ‘T’ time has passed. We observe that in this way we enable the TEE to securely measure time related events.
To justify our unique method for measuring time intervals, we note that while certain TEEs do offer a trusted time service (e.g. Intel SGX provides a function sgx_get_trusted_time), they only provide limited functionality. While good for some applications (like. HyperLedger PoET), the current consensus is that secure timing in TEEs is a hard problem to solve.
Once we have this tool inside the TEE we can create a simple “proof of life” – the testator should ping the TEE once every fixed period of time (e.g. 1 second), and once a valid beneficiary makes a claim over a bequeath, a VDF will be generated with a pre-configured parameter ‘T’ (e.g. 1 month). If a ping from the testator arrives before the VDF solution, the challenge and claim are cancelled. If no ping arrives before the VDF is solved, the TEE can safely determine that the testator was inactive for at least ‘T’ time and release the bequeath. Additionally, as part of the interface we defined, a beneficiary can check if the TEE holds a bequeath intended for it.
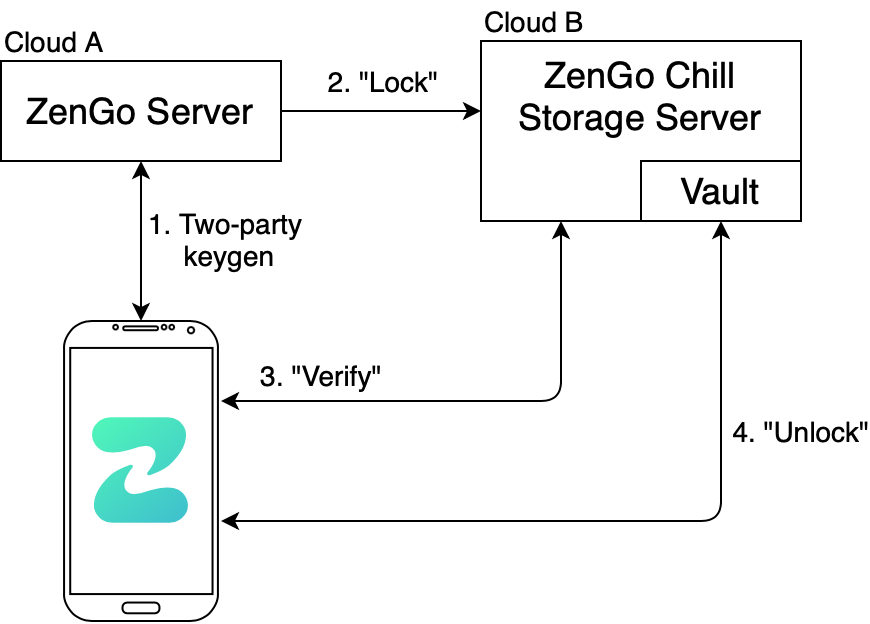
Putting it all together: Chill Storage 2.0 – The Protocol
We can now turn to describing the protocol. Our favorite analogy is that the TEE acts as a Vault, in which only the Zengo server can place secrets (shares) inside.
If a user wants to open the vault, two locks must be unlocked:
- User authentication – Authentication we get “for free”. We rely on the outputs of the key exchange protocol that are assumed to take place during distributed key generation before any server secret shared is locked.
- Zengo server is inactive for ‘T’ time – Server activity is measured based on the CryptoWill trick, using a VDF generated and verified inside a TEE.

In terms of security, all messages are sent encrypted. We can revise the protocol to provide the same functionality without the TEE learning the actual secret share, Essentially, this change would amount to the TEE keeping a key for the encrypted secret share held locally by the client, instead of the secret share itself, although it costs a bit more in the cryptography.
A per-client configuration is possible. First, the client may choose if to enable the service. Second, the time parameter ‘T’ can be determined by the client: one may want to use ‘T’ = 1-month while another client will prefer ‘T’ = 1-week for example.
Finally, the construction gives us almost ״for free״ a cross-cloud server backup. For this, we have two additional requirements:
- Running the TEE on a different cloud provider than the one Zengo server uses
- Adding an interface for the server to read secrets from the TEE
Demo
We use Intel SGX for TEE. Writing an SGX program is not like regular programming; in an enclave you cannot simply open a file and bind a socket. Essentially you can only allocate memory and run pure computations on it. If you need to go beyond that, (and you probably do), you have to engage in trickery. The most convenient way is to use frameworks, which in Rust are Rust SGX SDK from Apache incubator and Fortanix Rust Enclave Development Platform. They both add convenience to SGX programming, but still have limitations and specific design guidelines you need to follow.
Anjuna is another platform for developing enclave containers. It allows running any executable in an enclave without modifications. Anjuna wraps your application with Anjuna runtime and provides all the usual capabilities: networking, file system, etc. You also can configure it to encrypt files produced by the enclave using a hardware key which cannot be extracted from the enclave.
What we run inside of enclave is a simple key-value database mapping joint public key pk on server secret share sk_s. It provides a specific interface for accessing data, such that only the Zengo server is allowed to add records, and clients can only obtain a server’s share if they solved the latest VDF challenge.
We provide a recording of our demo here. The code (“Zengo Will”) can be found here. In terms of terminology, we refer to the server and client as testator and beneficiary. The TEE is called Will server.
Future Work (in the form of FAQ)
Here is a short list of practical considerations in working with Chill Storage 2.0.
Question: How can we guarantee the TEE will keep running in the event that the Zengo company shuts down?
Answer: This can be solved by committing to a payment plan that pays the cloud service provider three years in advance (in our case, Microsoft Azure). We will publicly share our payments schedule and receipts (possibly even paid via an on chain transaction). We have plans for second and third phases, but this is a topic for a separate blog post.
Question: How can we ensure a specific time ‘T’ matches a given wall-clock time? Wouldn’t a stronger machine be able to solve the VDF faster?
Answer: Zengo is a technology partner at the VDF alliance, a collaborative effort to design and implement production-grade VDFs in software and in hardware. The same VDF we use has other use cases in blockchains. We believe that this aligned interest between industry and academia will lead to the development of the most efficient VDF solver which will be made accessible to all. This is not just a vision but a reality. The parameter ‘T’ will be chosen with respect to this state of the art VDF hardware design.
Question: How do we plan to protect against hardware failures? On the one hand we must keep the state encrypted inside the enclave. On the other hand, replicating the TEE to another TEE poses a security risk because one TEE can be isolated from the network and miss a signal of life from the server.
Answer: While the cloud routinely snapshots its state and has the ability to backup from a snapshot, ultimately we plan on adapting the idea of running a consensus between TEEs. This concept, done in Signal app, lets TEEs agree on the current count of attempts to enter a correct PIN. Using the same consensus protocol, called RAFT, we plan to allow for multiple TEEs to maintain a replicated state while making sure no secret share will be revealed without a consensus on the current state. Out of 2n+1 TEEs, at least n TEEs must reach a consensus to change state and expose a secret.
Conclusions
We conclude this blog by providing a comparison between the existing Chill Storage (1.0) and our new protocol.
| ChillStorage 1.0 | ChillStorage 2.0 | |
| Third parties | There are 2 third parties: Trustee and Escrow. | We only use TEE which can be self deployed on another cloud (or in space) |
| Complex cryptography | Requires “Verifiable Encryption” (non-trivial cryptography developed in house) | “Verify” and “claim” both require simple proof of knowledge |
| Backup speed | Slow, mainly because of the cryptography | Fast |
| Recovery speed | Depends on a trigger from Trustee to Escrow | Depends on time parameter ‘T’ defined per client |
| Configurability | No opt-in, binary operation | Client can opt-in and define a policy for what is considered “server is dead” |
The table shows that in theory the new protocol holds superior properties over the existing one. Our proof of concept eliminated the most prominent risks, such as complexity of writing our logic to SGX.
Our next step is to turn our proof of concept into full implementation. As usual, our work is open source and can be found here. We wait for your feedback and contributions!
